
 Java的IO流进阶
Java的IO流进阶
# IO流进阶
# 字符类
# 字符流
1.字节流读取中文输出会存在什么问题?
- 会乱码。或者内存溢出。
2.读取中文输出,哪个流更合适,为什么?
- 字符流更合适,最小单位是按照单个字符读取的。
# 字符输入流
文件字符输入流:Reader
作用:以内存为基准,把磁盘文件中的数据以字符的形式读取到内存中去。
| 构造器 | 说明 |
|---|---|
| public FileReader(File file) | 创建字符输入流管道与源文件对象接通 |
| public FileReader(String pathname) | 创建字符输入流管道与源文件路径接通 |
| 方法名称 | 说明 |
|---|---|
| public int read() | 每次读取一个字符返回,如果字符已经没有可读的返回-1 |
| public int read(char[] buffer) | 每次读取一个字符数组,返回读取的字符个数,如果字符已经没有可读的返回-1 |
1.文件字符输入流,每次读取一个字符的api是哪个?
| 方法名称 | 说明 |
|---|---|
| public int read() | 每次读取一个字符返回,如果字节已经没有可读的返回-1 |
2.字符流的好处。每次读取一个字符存在什么问题?
- 读取中文字符不会出现乱码(如果代码文件编码一致)
- 性能较慢
# 一次读取一个字符
package com.itheima.d1_demo1;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.Reader;
public class FileReadDemo1 {
public static void main(String[] args) throws Exception {
// 读取每一个字符
// 创建一个字符输入流管道与源文件接通
Reader fr = new FileReader("file-io-app/src/data.txt");
// 读取一个字符返回,没有可读的字符了返回-1
int code = fr.read();
System.out.println((char) code);
int code1 = fr.read();
System.out.println((char) code1);
// 使用循环读取字符
int len;
while ((len = fr.read()) != -1){
System.out.println((char) len);
}
}
}
运行结果:
b
a
b
a
徐
# 读取一个字符数组
文件字符输入流:FileReader
作用:以内存为基准,把磁盘文件中的数据以字符的形式读取到内存中去。
| 方法名称 | 说明 |
|---|---|
| public int read() | 每次读取一个字符返回,如果字符已经没有可读的返回-1 |
| public int read(char[] buffer) | 每次读取一个字符数组,返回读取的字符数,如果字符已经没有可读的返回-1 |
package com.itheima.d1_demo1;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class FileReadDemo2 {
public static void main(String[] args) throws IOException {
Reader fr = new FileReader("file-io-app/src/data.txt");
// 用循环,每次读取一个字符数组的数据
char[] buffer = new char[1024];
int len;
while ((len = fr.read(buffer)) != -1){
String rs = new String(buffer,0,len);
System.out.println(rs);
}
}
}
运行结果:
ba徐
我是一个中国人aa
abc我是中国人aaa
abc我是
我是中国人
# 字符输出流
文件字符输出流:FileWriter
作用:以内存为基准,把内存中的数据以字符的形式写出到磁盘文件中去的流。
| 构造器 | 说明 |
|---|---|
| public FileWriter(File file) | 创建字符输出流管道与源文件对象接通 |
| public FileWriter(File file,boolean append) | 创建字符输出流管道与源文件对象接通,可追加数据 |
| public FileWriter(String filepath) | 创建字符输出流管道与源文件路径接通 |
| public FileWriter(String filepath,boolean append) | 创建字符输出流管道与源文件路径接通,可追加数据 |
文件字符输出流(FileWriter)写数据出去的API
| 方法名称 | 说明 |
|---|---|
| void write(int c) | 写一个字符 |
| void write(char[] cbuf) | 写入一个字符数组 |
| void write(char[] cbuf, int off, int len) | 写入字符数组的一部分 |
| void write(String str) | 写一个字符串 |
| void write(String str, int off, int len) | 写一个字符串的一部分 |
流的关闭与刷新
| 方法 | 说明 |
|---|---|
| flush() | 刷新流,还可以继续写数据 |
| close() | 关闭流,释放资源,但是在关闭之前会先刷新流。一旦关闭,就不能再写数据 |
package com.itheima.d1_demo1;
import java.io.FileWriter;
import java.io.Writer;
public class FileReadDemo3 {
public static void main(String[] args) throws Exception{
Writer fw = new FileWriter("file-io-app/src/data.txt"); // 覆盖管道,每次启动都会清空文件之前的数据
// public void write(int c): 写一个字符出去
fw.write(98);
fw.write('a');
fw.write('徐');
fw.write("\r\n");
// public void write(String c): 写一个字符串出去
fw.write("我是一个中国人aa");
fw.write("\r\n");
// public void write(char[] char): 写一个字符数组出去
char[] chars = "abc我是中国人aaa".toCharArray();
fw.write(chars);
fw.write("\r\n");
// public void write(String c,int pos,int len): 写字符串的一部分出去
fw.write("abc我是中国人",0,5);
fw.write("\r\n");
// public void write(char[] char,int pos,int len): 写字符数组的一部分出去
fw.write(chars,3,5);
fw.write("\r\n");
// fw.flush();
fw.close();
}
}
字节流、字符流的使用场景总结?
- 字节流适合做一切文件数据的拷贝(音视频,文本)
- 字节流不适合读取中文内容输出
- 字符流适合做文本文件的操作(读,写)
# 缓冲流
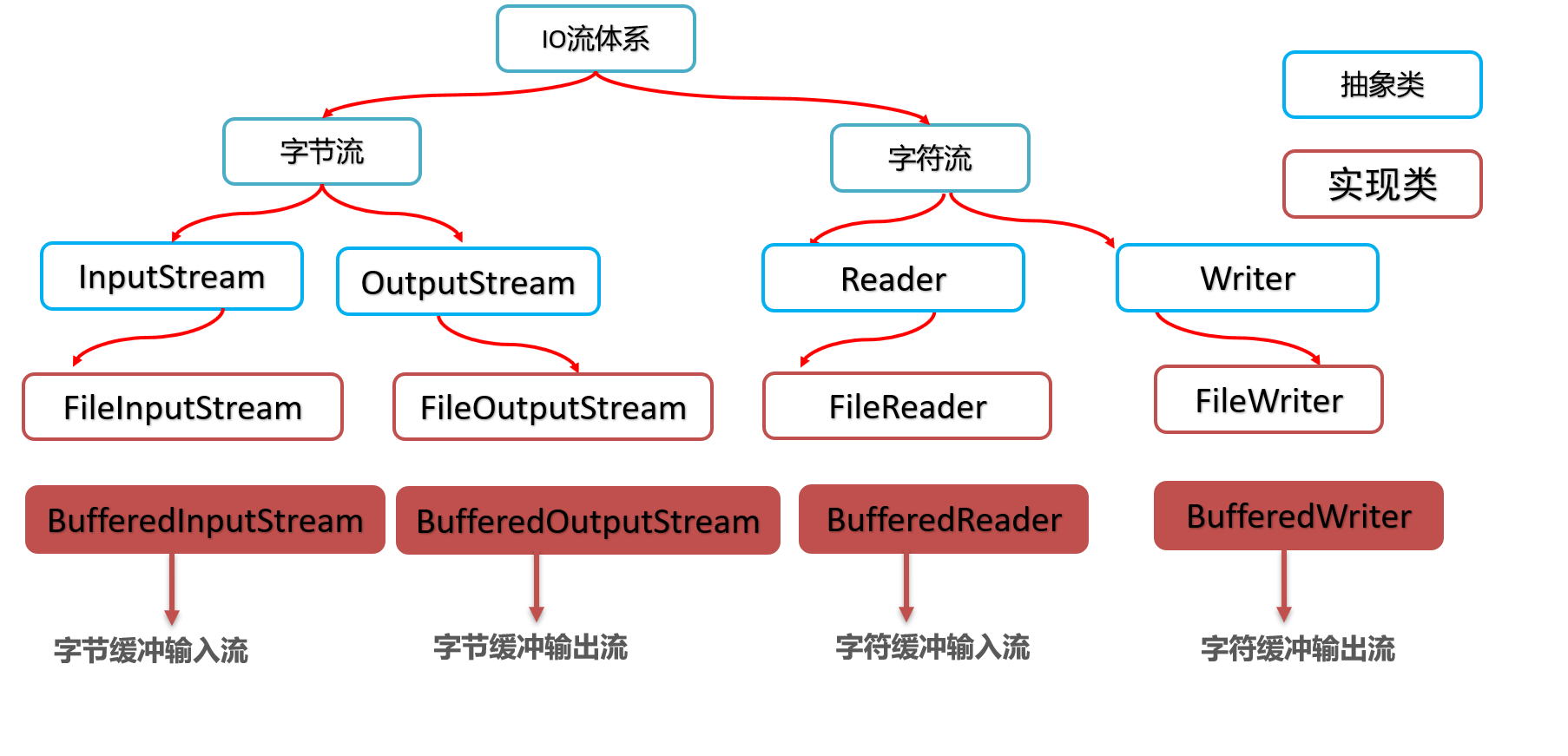
# 缓存流概述
- 缓冲流也称为高效流、或者高级流。之前学习的字节流可以称为原始流。
作用:缓冲流自带缓冲区、可以提高原始字节流、字符流读写数据的性能
字节缓冲流性能优化原理:
字节缓冲输入流自带了8KB缓冲池,以后我们直接从缓冲池读取数据,所以性能较好。
字节缓冲输出流自带了8KB缓冲池,数据就直接写入到缓冲池中去,写数据性能极高了。

# 字节缓冲流
字节缓冲输入流:BufferedInputStream,提高字节输入流读取数据的性能。
字节缓冲输出流:BufferedOutputStream,提高字节输出流读取数据的性能。
| 构造器 | 说明 |
|---|---|
| public BufferedInputStream(InputStream is) | 可以把低级的字节输入流包装成一个高级的缓冲字节输入流管道,从而提高字节输入流读数据的性能 |
| public BufferedOutputStream(OutputStream os) | 可以把低级的字节输出流包装成一个高级的缓冲字节输出流,从而提高写数据的性能 |
package com.itheima.d1_demo2;
import java.io.*;
public class ByteBufferDemo1 {
public static void main(String[] args) {
try (
// 1.创建一个字节输入流管道与原视频接通
InputStream is = new FileInputStream("file-io-app/src/out04.txt");
// 把原始的字节输入流包装成高级的缓冲字节输入流
InputStream bis = new BufferedInputStream(is);
// 2.创建一个字节输出流与目标文件接通
OutputStream os = new FileOutputStream("file-io-app/src/out05.txt");
// 把字节输出流管道包装成高级的缓冲字节输出管道
OutputStream bos = new BufferedOutputStream(os);
){
// 定义一个字节数组转移数据
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) != -1){
bos.write(buffer,0,len);
}
System.out.println("复制完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
复制完成
总结:
1.缓冲流的作用?
- 缓冲流自带缓冲区、可以提高原始字节流、字符流读写数据的性能
2.缓冲流有几种?
字节缓冲流
- 字节缓冲输入流:
BufferedInputStream - 字节缓冲输出流:
BufferedOutputStream
字符缓冲流
- 字符缓冲输入流:
BufferedReader - 字符缓冲输出流:
BufferedWriter
字节缓冲流为什么提高了操作数据的性能?
字节缓冲流自带8KB缓冲区可以提高原始字节流、字符流读写数据的性能
字节缓冲流的功能如何调用?
- public BufferedOutputStream(OutputStream os)
- public BufferedInputStream(InputStream is)
- 功能上并无很大变化,性能提升了。
# 字节缓冲流的性能分析
分析
①使用低级的字节流按照一个一个字节的形式复制文件。
②使用低级的字节流按照一个一个字节数组的形式复制文件。
③使用高级的缓冲字节流按照一个一个字节的形式复制文件。
④使用高级的缓冲字节流按照一个一个字节数组的形式复制文件。
// 使用低级的字节流按照一个一个字节的形式复制文件
private static void copy01() {
long startTime = System.currentTimeMillis();
try (
// 创建低级字节输入流与源文件的接通
InputStream is = new FileInputStream(STC_FILE);
// 创建低级字节输出流与目标文件的接通
OutputStream os = new FileOutputStream(DEST_FILE + "video1.mp4");
){
// 定义一个变量记录每次读取的字节 (一个一个复制)
int b;
while ((b = is.read()) != -1){
os.write(b);
}
}catch (Exception e){
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("低级字节流一个一个复制的文件耗时: " + (endTime - startTime) / 1000.0 + "s");
}
// 使用高级的缓冲字节流按照一个一个字节数组的形式复制文件
public static void copy2() {
try (
// 1.创建一个字节输入流管道与原视频接通
InputStream is = new FileInputStream("file-io-app/src/out04.txt");
// 把原始的字节输入流包装成高级的缓冲字节输入流
InputStream bis = new BufferedInputStream(is);
// 2.创建一个字节输出流与目标文件接通
OutputStream os = new FileOutputStream("file-io-app/src/out05.txt");
// 把字节输出流管道包装成高级的缓冲字节输出管道
OutputStream bos = new BufferedOutputStream(os);
){
// 定义一个字节数组转移数据
byte[] buffer = new byte[1024 * 8];
int len;
while ((len = is.read(buffer)) != -1){
bos.write(buffer,0,len);
}
System.out.println("复制完成");
} catch (Exception e) {
e.printStackTrace();
}
}
总结:
在以上的测试环境中,综合性能如下
- 使用高级缓冲字节流按照
一个一个字节的形式和一个一个字节数组的形式复制文件最快 - 使用低级的字节流按照一个一个字节的形式是最慢的
推荐使用哪种方式提高字节流读写数据的性能?
- 建议使用字节缓冲输入流、字节缓冲输出流,结合字节数组的方式,目前来看是性能最优的组合。
# 字符缓冲输出流
字符缓冲输出流:BufferedWriter。
作用:提高字符输出流写取数据的性能,除此之外多了换行功能
| 构造器 | 说明 |
|---|---|
| public BufferedWriter(Writer w) | 可以把低级的字符输出流包装成一个高级的缓冲字符输出流管道,从而提高字符输出流写数据的性能 |
字符缓冲输出流新增功能
| 方法 | 说明 |
|---|---|
| public void newLine() | 换行操作 |
package com.itheima.d1_demo3;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class BufferWriteDemo2 {
public static void main(String[] args) {
try (
// 创建字符输出流与目的源文件的接通
Writer w = new FileWriter("file-io-app/src/test2.txt");
// 将字符输出流包装成与高级缓冲的字符输出流
BufferedWriter bw = new BufferedWriter(w);
){
// 定义一个字符串
char[] buffer = "12345678".toCharArray();
bw.write("test");
bw.write("这里是测试");
bw.write("\r\n");
bw.write(buffer);
bw.write("abc我是中国人",0,5);
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
test这里是测试
12345678abc我是
总结:
1.字符缓冲流为什么提高了操作数据的性能?
字符缓冲流自带8K缓冲区可以提高原始字符流读写数据的性能
2.字符缓冲流的功能如何使用?
public BufferedReader(Reader r)
性能提升了,多了readLine()按照行读取的功能
public BufferedWriter(Writer w)
性能提升了,多了newLine()换行的功能
案例:把顺序错乱的文章进行恢复
分析:
①定义一个缓存字符输入流管道与源文件接通。
②定义一个List集合存储读取的每行数据。
③定义一个循环按照行读取数据,存入到List集合中去。
④对List集合中的每行数据按照首字符编号升序排序。
⑤定义一个缓存字符输出管道与目标文件接通。
⑥遍历List集合中的每个元素,用缓冲输出管道写出并换行。
如下是data.txt
3.a==这是测试
5.b==这是测试
1.c==这是测试
8.d==这是测试
4.e==这是测试
2.f==这是测试
9.g==这是测试
7.h==这是测试
6.j==这是测试
package com.itheima.d1_demo3;
import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class BufferRWDemo {
public static void main(String[] args) {
try (
// 创建缓冲字符输入流管道与文件接通
BufferedReader br = new BufferedReader(new FileReader("file-io-app/src/data.txt"));
// 创建缓冲字符输出流管道与文件接通
BufferedWriter bw = new BufferedWriter(new FileWriter("file-io-app/src/test3.txt"));
){
// 定义一个数组
List<String> data = new ArrayList<>();
// 定义循环,按照行读取文章
String line;
while ((line = br.readLine()) != null){
data.add(line);
}
// 定义自定义排序
List<String> list = new ArrayList<>();
Collections.addAll(list,"1","2","3","4","5","6","7","8","9");
Collections.sort(data, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return list.indexOf(o1.substring(0,o1.indexOf(".")))
- list.indexOf(o2.substring(0,o2.indexOf(".")));
}
});
System.out.println(data);
// 遍历集合中每行文章写出去,并且要换行
for (String datum : data) {
bw.write(datum);
bw.newLine();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
排序后的结果:
1.c==这是测试
2.f==这是测试
3.a==这是测试
4.e==这是测试
5.b==这是测试
6.j==这是测试
7.h==这是测试
8.d==这是测试
9.g==这是测试
# 转换流
# 思考
1、之前我们使用字符流读取中文是否有乱码?
- 没有的,因为代码编码和文件编码都是UTF-8。
2、如果代码编码和文件编码不一致,使用字符流直接读取还能不乱码吗?
- 会乱码。
- 文件编码和读取的编码必须一致才不会乱码。
# 字符输入转换流
字符输入转换流:InputStreamReader,可以把原始的字节流按照指定编码转换成字符输入流。
| 构造器 | 说明 |
|---|---|
| public InputStreamReader(InputStream is) | 可以把原始的字节流按照代码默认编码转换成字符输入流。几乎不用,与默认的FileReader一样。 |
| public InputStreamReader(InputStream is ,String charset) | 可以把原始的字节流按照指定编码转换成字符输入流,这样字符流中的字符就不乱码了(重点) |
需求:分别使用如下两种方式读取文件内容
①代码编码是UTF-8,文件编码也是UTF-8,使用字符流读取观察输出的中文字符结果。
②代码编码是UTF-8,文件编码使用GBK,使用字符流读取观察输出的中文字符结果
package com.itheima.d1_demo3;
import java.io.*;
public class CharSetTest00 {
public static void main(String[] args) {
try (
// 代码: UTF-8 文件 UTF-8 不会乱码
// 代码: UTF-8 文件 GBK 乱码
// 代码: UTF-8 文件: GBK
// 提取GBK文件的原始字节流
InputStream fr = new FileInputStream("file-io-app/src/data10.txt");
// 把原始字节流转换成字符输入流
//InputStreamReader isr = new InputStreamReader(fr); // 默认以UTF-8方式转换成字符流 还是会乱码
InputStreamReader isr = new InputStreamReader(fr,"GBK");
BufferedReader br = new BufferedReader(isr)
){
String line;
while ((line = br.readLine()) != null){
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
abc我爱中国
abc我爱中国
abc我爱中国
abc我爱中国
abc我爱中国
总结:
字符输入转换流InputStreamReader作用:
- 可以解决字符流读取不同编码乱码的问题
- public InputStreamReader(InputStream is,String charset):
- 可以指定编码把原始字节流转换成字符流,如此字符流中的字符不乱码。
# 字符输出转换流
字符输入转换流:OutputStreamWriter,可以把字节输出流按照指定编码转换成字符输出流。
| 构造器 | 说明 |
|---|---|
| public OutputStreamWriter(OutputStream os) | 可以把原始的字节输出流按照代码默认编码转换成字符输出流。几乎不用。 |
| public OutputStreamWriter(OutputStream os,String charset) | 可以把原始的字节输出流按照指定编码转换成字符输出流(重点) |
package com.itheima.d1_demo3;
import java.io.*;
public class CharSetTest01 {
public static void main(String[] args) {
try (
// 定义一个字节输出流
OutputStream os = new FileOutputStream("file-io-app/src/data11.txt");
// 把原始的字节输出流转换成字符输出流
Writer osw = new OutputStreamWriter(os,"GBK"); // 指定GBK的方式写字符写出去 是乱码的
// 把低级的字符输出流包装成高级的缓冲字符输出流
BufferedWriter br = new BufferedWriter(osw);
){
br.write("我爱中国1~~~");
br.write("我爱中国2~~~");
br.write("我爱中国3~~~");
} catch (Exception e) {
e.printStackTrace();
}
}
}
data11.txt的内容:
�Ұ��й�1~~~�Ұ��й�2~~~�Ұ��й�3~~~
# 序列化对象
# 对象序列化
作用:以内存为基准,把内存中的对象存储到磁盘文件中去,称为对象序列化。
使用到的流是对象字节输出流:ObjectOutputStream
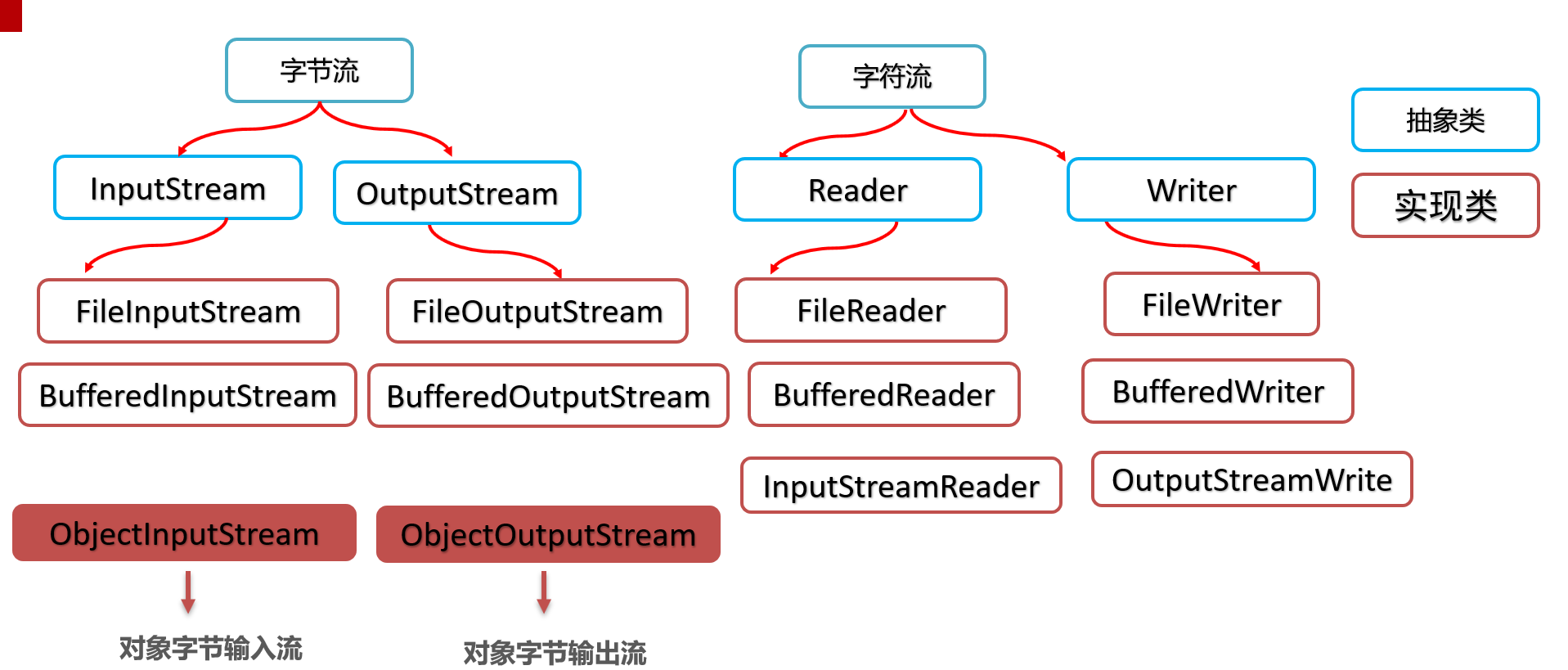
对象序列化
使用到的流是对象字节输出流:ObjectOutputStream
| 构造器 | 说明 |
|---|---|
| public ObjectOutputStream(OutputStream out) | 把低级字节输出流包装成高级的对象字节输出流 |
ObjectOutputStream序列化方法
| 方法名称 | 说明 |
|---|---|
| public final void writeObject(Object obj) | 把对象写出去到对象序列化流的文件中去 |
需要写一个对象
- 这里的transient是透明模式不参与序列化用于密码
- 一定要定义成接口类型
implements Serializable
package com.itheima.d1_demo4;
import java.io.Serializable;
public class Student implements Serializable {
// 申明序列化的版本号码
// 序列化的版本号与反序列化
private static final long serialVersionUID = 2
private String name;
private String loginName;
private transient String password; // 不参与序列化
private int age;
public Student() {
}
public Student(String name, String loginName, String password, int age) {
this.name = name;
this.loginName = loginName;
this.password = password;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getLoginName() {
return loginName;
}
public void setLoginName(String loginName) {
this.loginName = loginName;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", loginName='" + loginName + '\'' +
", password='" + password + '\'' +
", age=" + age +
'}';
}
}
package com.itheima.d1_demo4;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
public class ObjectOutputStreamDemo1 {
public static void main(String[] args) throws Exception{
// 创建一个对象
Student s = new Student("程雷","chenlei","123456",20);
// 对象序列化: 使用对象字节输出流包装字节输出流管道
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("file-io-app/src/obj.txt"));
// 直接调用序列化方法
oos.writeObject(s);
// 释放资源
oos.close();
}
}
总结:
1.对象序列化的含义是什么?
- 把对象数据存入到文件中去。
2.对象序列化用到了哪个流?
- 对象字节输出流ObjectOutputStram
- public void writeObject(Object obj)
3.序列化对象的要求是怎么样的?
- 对象必须实现序列化接口
# 对象反序列化
使用到的流是对象字节输入流:ObjectInputStream
作用:以内存为基准,把存储到磁盘文件中去的对象数据恢复成内存中的对象,称为对象反序列化。
| 构造器 | 说明 |
|---|---|
| public ObjectInputStream(InputStream out) | 把低级字节输如流包装成高级的对象字节输入流 |
ObjectInputStream序列化方法
| 方法名称 | 说明 |
|---|---|
| public Object readObject() | 把存储到磁盘文件中去的对象数据恢复成内存中的对象返回 |
package com.itheima.d1_demo4;
import java.io.FileInputStream;
import java.io.ObjectInputStream;
public class ObjectOutputStreamDemo2 {
public static void main(String[] args) throws Exception{
// 创建对象字节输入流管道包装成低级的字节输入管道
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("file-io-app/src/obj.txt"));
// 调用对象字节输入流的反序列化
Student s = (Student) ois.readObject();
System.out.println(s);
}
}
运行结果:
Student{name='程雷', loginName='chenlei', password='null', age=20}
总结:
1.对象反序列化的含义是什么?
- 把磁盘中的对象数据恢复到内存的Java对象中。
2.对象反序列化用到了哪个流?
- 对象字节输入流ObjectInputStram
- public Object readObject()
# 打印流
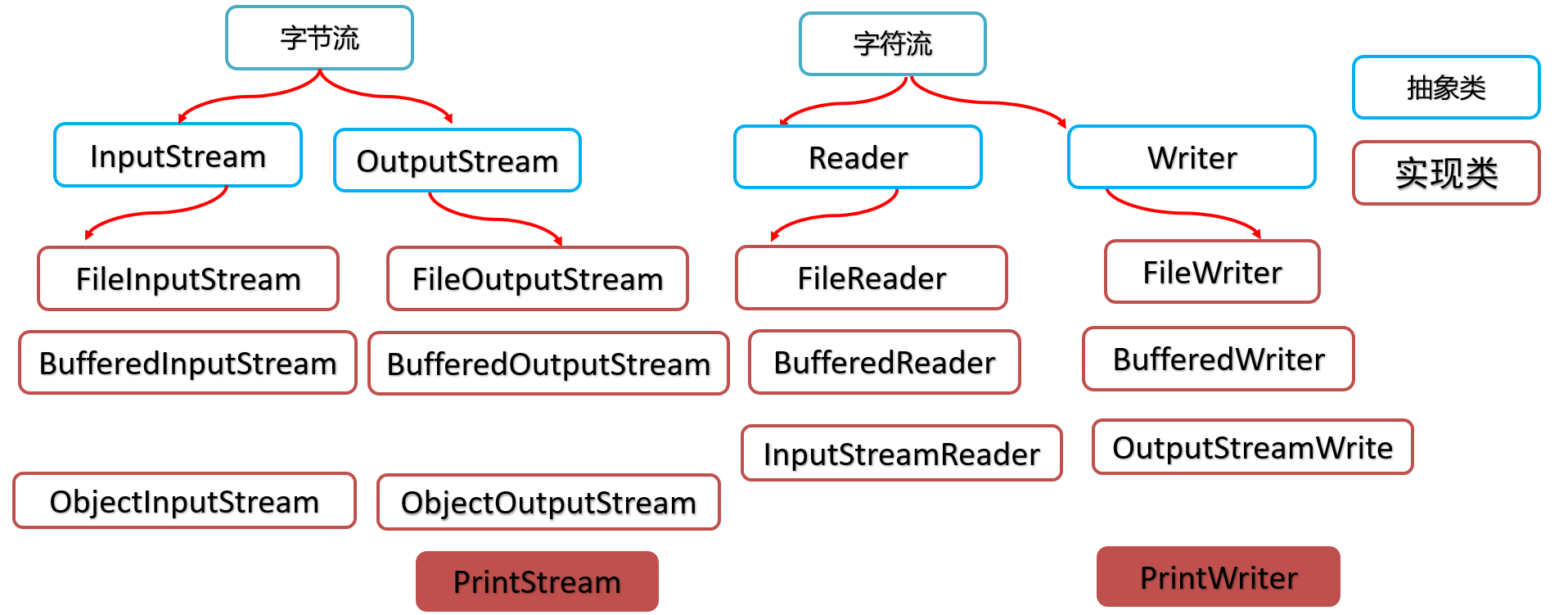
# 打印流
作用:打印流可以实现方便、高效的打印数据到文件中去。打印流一般是指:PrintStream,PrintWriter两个类。
可以实现打印什么数据就是什么数据,例如打印整数97写出去就是97,打印boolean的true,写出去就是true。
PrintStream
| 构造器 | 说明 |
|---|---|
| public PrintStream(OutputStream os) | 打印流直接通向字节输出流管道 |
| public PrintStream(File f) | 打印流直接通向文件对象 |
| public PrintStream(String filepath) | 打印流直接通向文件路径 |
| 方法 | 说明 |
|---|---|
| public void print(Xxx xx) | 打印任意类型的数据出去 |
PrintWriter
| 构造器 | 说明 |
|---|---|
| public PrintWriter(OutputStream os) | 打印流直接通向字节输出流管道 |
| public PrintWriter (Writer w) | 打印流直接通向字符输出流管道 |
| public PrintWriter (File f) | 打印流直接通向文件对象 |
| public PrintWriter (String filepath) | 打印流直接通向文件路径 |
| 方法 | 说明 |
|---|---|
| public void print(Xxx xx) | 打印任意类型的数据出去 |
package com.itheima.d1_demo5;
import java.io.FileNotFoundException;
import java.io.PrintWriter;
public class PrintDemo1 {
public static void main(String[] args) throws FileNotFoundException {
// 创建一个打印流对象
// PrintStream ps = new PrintStream(new FileOutputStream("file-io-app/src/ps.txt"));
// PrintStream ps = new PrintStream("file-io-app/src/ps.txt");
PrintWriter ps = new PrintWriter("file-io-app/src/ps.txt");
ps.println(97);
ps.println('a');
ps.println(true);
ps.println("这里是测试");
ps.close();
// 改变输出语句的位置(重定向)
}
}
这里会将打印的输出到文件中:
97
a
true
这里是测试
PrintStream和PrintWriter的区别
- 打印数据功能上是一模一样的,都是使用方便,性能高效(核心优势)
- PrintStream继承自字节输出流OutputStream,支持写字节数据的方法。
- PrintWriter继承自字符输出流Writer,支持写字符数据出去。
# 输出语句重定向
属于打印流的一种应用,可以把输出语句的打印位置改到文件。
基础语法:
PrintStream ps = new PrintStream("文件地址")
System.setOut(ps);
package com.itheima.d1_demo5;
import java.io.PrintStream;
public class PrintDemo2 {
public static void main(String[] args) throws Exception{
System.out.println("test");
PrintStream pr = new PrintStream("file-io-app/src/data12.txt");
System.setOut(pr);
// 这段是不会打印的
System.out.println("test");
}
}
运行结果:
test
# Properties
以后我们系统中,可能会有一个.properties结尾的属性文件
# Properties属性集对象
其实就是一个Map集合,但是我们一般不会当集合使用,因为HashMap更好用。
Properties核心作用:
- Properties代表的是一个属性文件,可以把自己对象中的键值对信息存入到一个属性文件中去。
- 属性文件:后缀是.properties结尾的文件,里面的内容都是 key=value,后续做系统配置信息的。
# Properties的API
Properties和IO流结合的方法:
| 构造器 | 说明 |
|---|---|
| void load(InputStream inStream) | 从输入字节流读取属性列表(键和元素对) |
| void load(Reader reader) | 从输入字符流读取属性列表(键和元素对) |
| void store(OutputStream out, String comments) | 将此属性列表(键和元素对)写入此 Properties表中,以适合于使用 load(InputStream)方法的格式写入输出字节流 |
| void store(Writer writer, String comments) | 将此属性列表(键和元素对)写入此 Properties表中,以适合使用 load(Reader)方法的格式写入输出字符流 |
| public Object setProperty(String key, String value) | 保存键值对(put) |
| public String getProperty(String key) | 使用此属性列表中指定的键搜索属性值 (get) |
public Set<String> stringPropertyNames() | 所有键的名称的集合 (keySet()) |
将内容输入到.properties结尾的属性文件
package com.itheima.d1_demo5;
import java.io.FileWriter;
import java.util.Properties;
public class PropertiesDemo1 {
public static void main(String[] args) throws Exception{
// 需求: 使用Properties把键值对信息存入到属性文件中去
Properties properties = new Properties();
properties.setProperty("admin","1123456");
properties.setProperty("test","1123456");
properties.setProperty("heima","1123456");
System.out.println(properties);
/*
参数1:保存管道 字符输入流管道
参数2:保存心得
*/
properties.store(new FileWriter("file-io-app/src/users.properties"),
"this is user!");
}
}
从users.properties文件中读取属性列表的键值对
package com.itheima.d1_demo5;
import java.io.FileReader;
import java.util.Properties;
public class PropertiesDemo2 {
public static void main(String[] args) throws Exception{
// 需求: Properties读取属性文件中的键值对信息。 (读取)
Properties properties = new Properties();
System.out.println(properties);
// 加载属性文件中的键值对数据到属性对象properties中去
properties.load(new FileReader("file-io-app/src/users.properties"));
System.out.println(properties);
String rs = properties.getProperty("admin");
String rs1 = properties.getProperty("test");
System.out.println(rs);
System.out.println(rs1);
}
}
运行结果:
{}
{admin=1123456, test=1123456, heima=1123456}
1123456
1123456
总结:
Properties的作用?
可以存储Properties属性集的键值对数据到属性文件中去:
nvoid store(Writer writer, String comments)
可以加载属性文件中的数据到Properties对象中来:
nvoid load(Reader reader)
# IO框架
# commons-io概述
commons-io是apache开源基金组织提供的一组有关IO操作的类库,可以提高IO功能开发的效率。
commons-io工具包提供了很多有关io操作的类。有两个主要的类FileUtils, IOUtils
# FileUtils方法
| 方法名 | 说明 |
|---|---|
| String readFileToString(File file, String encoding) | 读取文件中的数据, 返回字符串 |
| void copyFile(File srcFile, File destFile) | 复制文件。 |
| void copyDirectoryToDirectory(File srcDir, File destDir) | 复制文件夹。 |
导入commons-io-2.6.jar做开发
需求
使用commons-io简化io流读写
分析
①在项目中创建一个文件夹:lib
②将commons-io-2.6.jar文件复制到lib文件夹
③在jar文件上点右键,选择 Add as Library -> 点击OK
在类中导包使用
package com.itheima.d1_demo5;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.nio.file.Files;
import java.nio.file.Path;
public class CommonsIODemo1 {
public static void main(String[] args) throws Exception {
// 完成文件复制
IOUtils.copy(new FileInputStream("D:\\Devops\\test\\data.txt"),
new FileOutputStream("D:\\Devops\\test2\\data.txt"));
// 完成文件复制到某个文件夹下
FileUtils.copyFileToDirectory(new File("D:\\Devops\\test\\data.txt"),
new File("D:\\Devops\\test2"));
// 完成文件夹复制到某个文件夹
FileUtils.copyDirectoryToDirectory(new File("D:\\test"),new File("D:\\test3"));
FileUtils.deleteDirectory(new File("D:\\test"));
// JDK1.7 自己也做了一些代码完成复制的操作: New IO的技术
Files.copy("D:\\Devops\\test\\data.txt","D:\\Devops\\test2\\data.txt");
Files.deleteIfExists(Path.of("D:\\test"));
}
}