
 为系统守护进程预留计算资源
为系统守护进程预留计算资源
# 为系统守护进程预留计算资源
Kubernetes 的节点可以按照 Capacity 调度。默认情况下 pod 能够使用节点全部可用容量。 这是个问题,因为节点自己通常运行了不少驱动 OS 和 Kubernetes 的系统守护进程。 除非为这些系统守护进程留出资源,否则它们将与 pod 争夺资源并导致节点资源短缺问题
kubelet 公开了一个名为 'Node Allocatable' 的特性,有助于为系统守护进程预留计算资源。 Kubernetes 推荐集群管理员按照每个节点上的工作负载密度配置 Node Allocatable
# 节点可分配
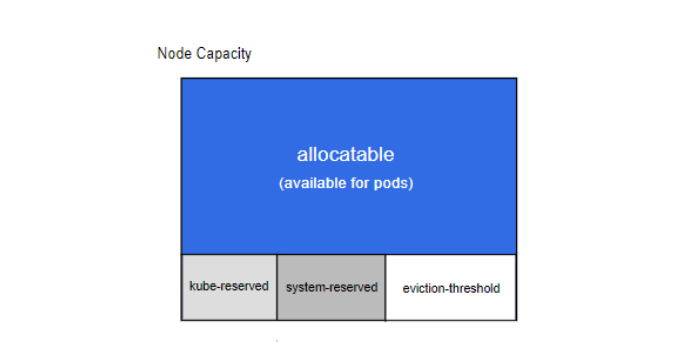
'Allocatable' 被定义为 pod 可用计算资源量。调度器不会超额申请 'Allocatable'。目前支持 CPU, memory 和 ephemeral-storage 参数
# 启动Qos和Pod级别的cgroups
为了恰当的在节点范围实施节点可分配约束,你必须通过 --cgroups-per-qos 标志启用新的 cgroup 层次结构。这个标志是默认启用的。
启用后,kubelet 将在其管理的 cgroup 层次结构中创建所有终端用户的 Pod
# 配置cgroup驱动
kubelet 支持在主机上使用 cgroup 驱动操作 cgroup 层次结构。驱动通过 --cgroup-driver 标志配置
支持的参数值如下:
cgroupfs是默认的驱动,在主机上直接操作 cgroup 文件系统以对 cgroup 沙箱进行管理systemd是可选的驱动,使用 init 系统支持的资源的瞬时切片管理 cgroup 沙箱
取决于相关容器运行时的配置,操作员可能需要选择一个特定的 cgroup 驱动 来保证系统正常运行
# 配置资源预留
通过 Kubectl describe node 命令查看节点可分配资源的数据
[root@master ~]# kubectl describe nodes master
...
Capacity:
cpu: 4
ephemeral-storage: 104846316Ki
hugepages-2Mi: 0
memory: 8009440Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 96626364666
hugepages-2Mi: 0
memory: 7907040Ki
pods: 110
Capacity:所有资源
Allocatable :分配资源
# Kube预留值
方法一
要选择性地对 kubernetes 系统守护进程上执行kube-reserved保护,需要把 kubelet 的--kube-reserved-cgroup标志的值设置为 kube 守护进程的父控制组。推荐将 kubernetes 系统守护进程放置于顶级控制组之下。理想情况下每个系统守护进程都应该在其自己的子控制组中运行。
请注意,如果
--kube-reserved-cgroup不存在,Kubelet 将 不会 创建它。 如果指定了一个无效的 cgroup,Kubelet 将会失败
- Kubelet 标志:
--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000] - Kubelet 标志:
--kube-reserved-cgroup=
kubernetes 系统守护进程记述其资源预留值。该配置并非用来给以 Pod 形式运行的系统守护进程保留资源。kube-reserved 通常是节点上 pod 密度 的函数。
除了 cpu,内存 和 ephemeral-storage 之外,pid 可用来指定为 kubernetes 系统守护进程预留指定数量的进程 ID。
- 修改/var/lib/kubelet/config.yaml
[root@master ~]# cat /var/lib/kubelet/config.yaml
···
enforceNodeAllocatable:
- pods
- kube-reserved # 开启 kube 预留资源
kubeReserved:
cpu: 500m
memory: 1Gi
ephemeral-storage: 1Gi
kubeReservedCgroup: /kubelet.slice # 指定 kube 资源预留的 cgroup
- 重启服务
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart kubelet
[root@master ~]# journalctl -u kubelet.service -f
'报错:'
Apr 13 11:04:44 master kubelet[30669]: F0413 11:04:44.171621 30669 kubelet.go:1383] Failed to start ContainerManager Failed to enforce Kube Reserved Cgroup Limits on "/kubelet.slice": ["kubelet"] cgroup does not exist
Apr 13 11:04:44 master systemd[1]: kubelet.service: main process exited, code=exited, status=255/n/a
Apr 13 11:04:44 master systemd[1]: Unit kubelet.service entered failed state.
Apr 13 11:04:44 master systemd[1]: kubelet.service failed.
指定的 kubelet 这个 cgroup 不存在,但是由于子系统较多,具体是哪一个子系统不存在不好定位,我们可以将 kubelet 的日志级别调整为
v=4,就可以看到具体丢失的 cgroup 路径
- 修改/var/lib/kubelet/kubeadm-flags.env
[root@master ~]# cat /var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--v=4 --container-runtime=remote --container-runtime-endpoint=/run/containerd/containerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.6"
- 再次重启
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart kubelet
- 查看到具体不存在的路径
[root@master ~]# systemctl daemon-reload
Apr 13 11:07:24 master kubelet[2501]: I0413 11:07:24.753039 2501 cgroup_manager_linux.go:276] The Cgroup [kubelet] has some missing paths: [/sys/fs/cgroup/cpuset/kubelet.slice /sys/fs/cgroup/cpu,cpuacct/kubelet.slice /sys/fs/cgroup/systemd/kubelet.slice /sys/fs/cgroup/pids/kubelet.slice /sys/fs/cgroup/cpu,cpuacct/kubelet.slice /sys/fs/cgroup/hugetlb/kubelet.slice /sys/fs/cgroup/memory/kubelet.slice]
- 创建路径
[root@master ~]# mkdir -p /sys/fs/cgroup/cpuset/kubelet.slice
[root@master ~]# mkdir -p /sys/fs/cgroup/cpu,cpuacct/kubelet.slice
[root@master ~]# mkdir -p /sys/fs/cgroup/systemd/kubelet.slice
[root@master ~]# mkdir -p /sys/fs/cgroup/pids/kubelet.slice
[root@master ~]# mkdir -p /sys/fs/cgroup/cpu,cpuacct/kubelet.slice
[root@master ~]# mkdir -p /sys/fs/cgroup/hugetlb/kubelet.slice
[root@master ~]# mkdir -p /sys/fs/cgroup/memory/kubelet.slice
- 再次重启并查看,发现一切正常就ok了
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart kubelet
[root@master ~]# journalctl -u kubelet -f
......
Sep 09 17:57:36 ydzs-node4 kubelet[20427]: I0909 17:57:36.382811 20427 cgroup_manager_linux.go:273] The Cgroup [kubelet] has some missing paths: [/sys/fs/cgroup/cpu,cpuacct/kubelet.slice /sys/fs/cgroup/memory/kubelet.slice /sys/fs/cgroup/systemd/kubelet.slice /sys/fs/cgroup/pids/kubelet.slice /sys/fs/cgroup/cpu,cpuacct/kubelet.slice /sys/fs/cgroup/cpuset/kubelet.slice]
Sep 09 17:57:36 ydzs-node4 kubelet[20427]: I0909 17:57:36.383002 20427 factory.go:170] Factory "systemd" can handle container "/system.slice/run-docker-netns-db100461211c.mount", but ignoring.
Sep 09 17:57:36 ydzs-node4 kubelet[20427]: I0909 17:57:36.383025 20427 manager.go:908] ignoring container "/system.slice/run-docker-netns-db100461211c.mount"
Sep 09 17:57:36 ydzs-node4 kubelet[20427]: F0909 17:57:36.383046 20427 kubelet.go:1381] Failed to start ContainerManager Failed to enforce Kube Reserved Cgroup Limits on "/kubelet.slice": ["kubelet"] cgroup does not exist
- 可以通过查看 cgroup 里面的限制信息校验是否配置成功(查看内存的限制信息
[root@master ~]# cat /sys/fs/cgroup/memory/kubelet.slice/memory.limit_in_bytes
1073741824
- 查看节点信息
Capacity:
cpu: 4
ephemeral-storage: 104846316Ki
hugepages-2Mi: 0
memory: 8009440Ki
pods: 110
Allocatable:
cpu: 3500m
ephemeral-storage: 95552622842
hugepages-2Mi: 0
memory: 6858464Ki
pods: 110
可以看到分配的 Allocatable 值就变成了 Kube 预留过后的值了,证明 Kube 预留成功了
方法二
- 查看节点信息
Capacity:
cpu: 4
ephemeral-storage: 104846316Ki
hugepages-2Mi: 0
memory: 8009440Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 96626364666
hugepages-2Mi: 0
memory: 7907040Ki
pods: 110
- 修改/etc/sysconfig/kubelet
[root@master ~]# vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS='--system-reserved=cpu=100m,memory=1Gi,ephemeral-storage=1Gi'
- 重启并查看
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart kubelet
[root@master ~]# kubectl describe nodes master
Capacity:
cpu: 4
ephemeral-storage: 104846316Ki
hugepages-2Mi: 0
memory: 8009440Ki
pods: 110
Allocatable:
cpu: 3900m
ephemeral-storage: 95552622842
hugepages-2Mi: 0
memory: 6858464Ki
pods: 110
# 驱逐阈值
- Kubelet 标志:
--eviction-hard=[memory.available<500Mi]
节点级别的内存压力将导致系统内存不足,这将影响到整个节点及其上运行的所有 Pod。节点可以暂时离线直到内存已经回收为止。
为了防止(或减少可能性)系统内存不足,kubelet 提供了 资源不足 管理。驱逐操作只支持memory 和 ephemeral-storage。通过--eviction-hard标志预留一些内存后,当节点上的可用内存降至保留值以下时,kubelet将尝试驱逐 Pod。 如果节点上不存在系统守护进程,Pod 将不能使用超过capacity-eviction-hard所指定的资源量。因此,为驱逐而预留的资源对 Pod 是不可用的
上面我们还提到可分配的资源还和 kubelet 驱逐的阈值有关。节点级别的内存压力将导致系统内存不足,这将影响到整个节点及其上运行的所有 Pod,节点可以暂时离线直到内存已经回收为止,我们可以通过配置 kubelet 驱逐阈值来防止系统内存不足。驱逐操作只支持内存和 ephemeral-storage 两种不可压缩资源。当出现内存不足时,调度器不会调度新的 Best-Effort QoS Pods 到此节点,当出现磁盘压力时,调度器不会调度任何新 Pods 到此节点。
我们这里为master节点配置如下所示的硬驱逐阈值:
[root@master ~]# /var/lib/kubelet/config.yaml
......
evictionHard: # 配置硬驱逐阈值
memory.available: "300Mi"
nodefs.available: "10%"
enforceNodeAllocatable:
- pods
- kube-reserved
kubeReserved:
cpu: 500m
memory: 1Gi
ephemeral-storage: 1Gi
kubeReservedCgroup: /kubelet.slice
......
# 显式保留的 CPU 列表
特性状态: Kubernetes v1.17 [stable]
Kubelet 标志: --reserved-cpus=0-3
reserved-cpus 旨在为操作系统守护程序和 kubernetes 系统守护程序保留一组明确指定编号的 CPU。reserved-cpus 适用于不打算针对 cpuset 资源为操作系统守护程序和 kubernetes 系统守护程序定义独立的顶级 cgroups 的系统。
如果 Kubelet 没有 指定参数 --system-reserved-cgroup 和 --kube-reserved-cgroup,则 reserved-cpus 的设置将优先于 --kube-reserved 和 --system-reserved 选项。
# 实施节点可分配约束
Kubelet 标志: --enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved]
调度器将 'Allocatable' 视为 Pod 可用的 capacity(资源容量)。
kubelet 默认对 Pod 执行 'Allocatable' 约束。 无论何时,如果所有 Pod 的总用量超过了 'Allocatable',驱逐 Pod 的措施将被执行。可通过设置 kubelet --enforce-node-allocatable 标志值为 pods 控制这个措施。
可选地,通过在同一标志中同时指定 kube-reserved 和 system-reserved 值, 可以使 kubelet 强制实施 kube-reserved 和 system-reserved约束。
请注意,要想执行
kube-reserved或者system-reserved约束,需要对应设置--kube-reserved-cgroup或者--system-reserved-cgroup