
 Redis详解
Redis详解
# Redis的详解
# 1.NoSql数据库
# 1.1 NoSQL数据库介绍
NoSQL(NoSQL = Not Only SQL),意思即是“不仅仅是SQL”,泛指非关系型的数据库 NoSQL不依赖业务逻辑方式存储,而似简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
- 不遵循SQL标准
- 不支持ACID
- 超远于SQL的性能
# 1.2 NoSQL适用场景
- 对数据高并发的读写
- 海量数据的读写
- 对数据高可扩展性的
# 1.3 Redis概述
Redis 是一个开源的 key-value 存储系统。
和 Memcached 类似,它支持存储的 value 类型相对更多,包括
string(字符串)、list(链表)、set(集合)、zset(sorted set –有序集合) 和hash(哈希类型)。这些数据类型都支持
push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,Redis 支持各种不同方式的排序。
与 memcached 一样,为了保证效率,数据都是缓存在内存中。
区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
并且在此基础上实现了
master-slave (主从)同步。
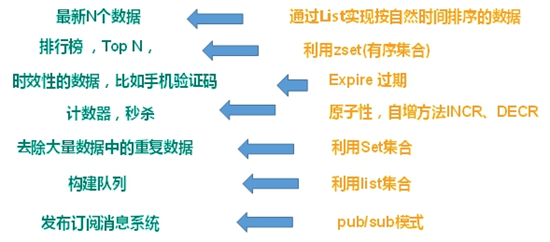
应用场景
配合关系型数据库做高速缓存
- 高频次,热门访问的数据,降低数据库 IO。
- 分布式架构,做 session 共享。

多样的数据结构存储持久化数据
# 1.4 Redis的架构
Redis 使用的是单线程 + 多路 IO 复用技术:
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用 select 和 poll 函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
串行 vs 多线程 + 锁(memcached) vs 单线程 + 多路 IO 复用 (Redis)(与 Memcache 三点不同:支持多数据类型,支持持久化,单线程 + 多路 IO 复用) 。
相关的知识:
- 默认16个数据库,类似数组下标从0开始,初始默认使用0号库
- 使用命令
select <dbid>来切换数据库。 - 统一密码管理,所有库同样密码
dbsize查看当前数据库的key的数量flushdb清空当前数据库flushall通杀全部库
# 2. Redis的安装
这里的Redis使用的是Docker的环境安装,如果不考虑Redis的分布式集群以及哨兵的问题,可以使用Docker的方式 启动Redis,我这里使用的是CentOS的镜像手写Dockerfile的方式使用Docker-compose的方式管理Redis。
# 2.1编写Dockerfile
使用的是CentOS的yum源,这样安装的Redis随时可以删除也可以重新安装。
FROM centos:centos7.9.2009
MAINTAINER Chinaskills
RUN rm -rf /etc/yum.repos.d/*
COPY local.repo /etc/yum.repos.d/
COPY yum /root/yum
RUN yum -y install redis
RUN sed -i 's/127.0.0.1/0.0.0.0/g' /etc/redis.conf && \
sed -i 's/protected-mode yes/protected-mode no/g' /etc/redis.conf
EXPOSE 6379
CMD ["/usr/bin/redis-server","/etc/redis.conf"]
# 2.2 配置Compose
使用docker-compose的方式管理Redis会方便很多,很好运维。
version: "3.0"
services:
Redis:
image: redis:v1.0
container_name: redis-nosql
ports:
- "6379:6379"
restart: always
hostname: redis
# 2.3 部署查看状态
在后台将镜像跑起来之后,可以进入容器操作。
root@administrator:~/redis# docker-compose up -d
root@administrator:~/redis# docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------------
redis-nosql /usr/bin/redis-server /etc ... Up 0.0.0.0:6379->6379/tcp,:::6379->6
379/tcp
root@administrator:~/redis# docker exec -it redis-nosql /bin/bash
[root@redis /]# redis-cli
127.0.0.1:6379>
# 2.4 Redis键(key)
keys *查看当前所有的key(匹配: keys *1)exists key判断某个key是否存在type key查看你的key是什么类型del key删除value选择非阻塞删除- 仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
expire key 1010秒钟: 为给定的key设置国企时间ttl key查看还有多少秒过期 , -1表示永远不过期,-表示已经过期
# 查看所有的key
127.0.0.1:6379> keys *
1) "ke2"
2) "key3"
# 判断是否存在
127.0.0.1:6379> exists ke2
(integer) 1
# 查看当前的key的类型
127.0.0.1:6379> type ke2
string
# 删除当前的key
127.0.0.1:6379> del ke2
(integer) 1
127.0.0.1:6379> keys *
1) "key3"
# 设置当前的key过期时间
127.0.0.1:6379> expire key3 10
(integer) 1
127.0.0.1:6379> ttl key3
(integer) 0
127.0.0.1:6379> ttl key3
(integer) -2
# 3. 数据类型
# 3.1 Redis字符串(String)
概述
String 是 Redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
String 类型是二进制安全的。意味着 Redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象。
String 类型是 Redis 最基本的数据类型,一个 Redis 中字符串 value 最多可以是 512M。
数据结构 String 的数据结构为简单动态字符串 (Simple Dynamic String, 缩写 SDS),是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.
如图中所示,内部为当前字符串实际分配的空间 capacity 一般要高于实际字符串长度 len。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是字符串最大长度为 512M。
# 3.2 字符串常用命令
1.添加键值对
set <key><value> 添加键值对
127.0.0.1:6379> set key value [EX seconds] [PX milliseconds] [NX|XX]
- NX: 当数据库中的key不存在时,可以将key-value添加数据库
- XX: 当数据库中的key存在时,可以将key-value添加数据库,与NX参数互斥
- EX:key的超时参数
- PX:key的超时毫秒数,与EX互斥
2.查询对应键值
get <key>
实例:
127.0.0.1:6379> set k1 100
OK
127.0.0.1:6379> set k2 200
OK
127.0.0.1:6379> get k1
"100"
127.0.0.1:6379> get k2
"200"
3.将给定的value追加到原值的末尾
append <key><value>
4.获取key的长度
strlen <key>
5.只有key不存在的时候,设置key的值
setnx <key><value>
实例:
# 查询当前的所有键值对
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
127.0.0.1:6379> append k1 abc
(integer) 6
127.0.0.1:6379> get k1
"100abc"
127.0.0.1:6379> strlen k1
(integer) 6
127.0.0.1:6379> setnx k3 300
(integer) 1
# 这里可以看到k2无法再设置key的值
127.0.0.1:6379> setnx k2 200
(integer) 0
6.将key中存储的数字增值1,只能对数字值操作,如果为空,新增值为1
incr <key>
7.将key中存储的数字值减1,只能对数字值操作,如果为空,新增值为-1
decr <key>
8.将key中存储的数字值增减,自定义步长
incrby/decrby <key><步长>
实例:
127.0.0.1:6379> incr k2
(integer) 201
127.0.0.1:6379> decr k2
(integer) 200
127.0.0.1:6379> incrby k2 10
(integer) 210
127.0.0.1:6379> decrby k2 10
(integer) 200
9.同时设置一个或多个key和value
mset <key1><value1> <key2><value2>
10.同时获取一个或多个value
msetnx <key1><value1><key2><value2>....
注意: 同时设置一个或者多个key-value对,当前仅当所有给定的key都不存在。
实例:
127.0.0.1:6379> mset k4 v1 k5 v2 k6 v3
OK
127.0.0.1:6379> keys *
3) "k6"
5) "k5"
6) "k4"
127.0.0.1:6379> mget k4 k5 k6
1) "v1"
2) "v2"
3) "v3"
11.获取值的范围,类似java的substring,前包,后包
getrange <key><起始位置><结束位置>
12.用value覆写key所存储的字符串值,从起始位置开始(索引从0开始)
setrange <key><起始位置><value>
实例:
127.0.0.1:6379> set key7 abcdefg
OK
127.0.0.1:6379> getrange key7 0 3
"abcd"
127.0.0.1:6379> setrange key7 3 666
(integer) 7
127.0.0.1:6379> get key7
"abc666g"
127.0.0.1:6379>
13.设置键值的同时,设置过期时间,单位秒
setex <key><过期时间><value>
14.以新换旧,设置了新值同时获得旧的值
getset <key><value>
实例:
127.0.0.1:6379> setex key8 5 v8
OK
127.0.0.1:6379> getset key7 abc
"abc666g"
127.0.0.1:6379> get key7
"abc"
# 3.3 Redis列表(List)
概述
单键多值: Redis列表是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边)。它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

数据结构
- List 的数据结构为快速链表 quickList。
- 首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
- 当数据量比较多的时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next。

- Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
# 3.4 列表常用命令
1.从左边或者右边插入一个或者多个值
lpush / rpush <key><value1><value2><value3>
2.从左边或者右边吐出一个值,值在键在,值光键值亡
lpop / rpop <key>
3.列表从右边吐出一个值,插入到另外列表的左边
rpoplpush <key1><key2>从<key1>
4.按照索引下标获得元素(从左到右)
lrange <key><start><stop>
实例:
# 从左边插入value到key中
127.0.0.1:6379> lpush k1 v1 v2 v3
(integer) 3
127.0.0.1:6379> lpush k2 v1 v2 v3
(integer) 5
# 从右往左边吐出k2
127.0.0.1:6379> lpop k2
"v3"
127.0.0.1:6379> lpop k2
"v2"
127.0.0.1:6379> lpop k2
"v1"
# 从k2 吐出 插入到k1
127.0.0.1:6379> lpush k1 v1 v2 v3
(integer) 3
127.0.0.1:6379> lpush k2 v1 v2 v3
(integer) 3
127.0.0.1:6379> rpoplpush k2 k1
"v1"
# 使用索引下标查询
127.0.0.1:6379> lrange k1 0 4
1) "v1"
2) "v3"
3) "v2"
4) "v1"
5.按照索引下标获得元素
lindex <key><index>
6.获得列表长度
llen <key>
7.在value的后面插入新的值
linsert <key> before <value><newvalue>
8.从左边删除n个value
lrem <key><n><value>
9.将列表key下标为index的值替换为value
lset <key><index><value>
实例:
# 获得元素
127.0.0.1:6379> lindex k2 1
"v2"
# 获得长度
127.0.0.1:6379> llen k2
(integer) 2
127.0.0.1:6379> linsert k2 before v2 v5
(integer) 3
# 从左边删除n个
127.0.0.1:6379> lrem k2 3 v1
(integer) 0
127.0.0.1:6379> lset k2 0 v1
OK
# 3.5 Redis 集合(Set)
概述
Redis set 对外提供的功能与 list 类似,是一个列表的功能,特殊之处在于 set 是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。
Redis 的 Set 是 string 类型的无序集合。它底层其实是一个
value为null的hash表,所以添加,删除,查找的复杂度都是 O (1)。一个算法,随着数据的增加,执行时间的长短,如果是 O (1),数据增加,查找数据的时间不变。
数据结构
- Set 数据结构是 dict 字典,字典是用哈希表实现的。
- Java 中 HashSet 的内部实现使用的是 HashMap,只不过所有的 value 都指向同一个对象。Redis 的 set 结构也是一样,它的内部也使用 hash 结构,所有的 value 都指向同一个内部值。
# 3.6 集合的常用命令
1.将一个或者多个member元素加入到集合key中,已经存在的member元素将被忽略
sadd <key><value1><value2>
2.取出该集合的所有值
smembers <key>
3.判断集合key是否含有该value的值,有1,没有0
sismember <key><value>
4.返回该集合的元素个数
scard <key>
5.删除集合的某个元素
srem <key><value1><value2>
6.随机从该集合中吐出一个值
spop <key>
7.随机从该集合中取出n个值,不会从集合中删除
srandmember <key><n>
8.把集合中一个值从一个集合移动到另一个集合
smove <source><destination> value
实例:
# 添加一个集合
127.0.0.1:6379> sadd k1 v1 v2 v3
(integer) 3
# 获取集合的所有数据
127.0.0.1:6379> smembers k1
1) "v1"
2) "v3"
3) "v2"
# 判断是否存在
127.0.0.1:6379> sismember k1 v2
(integer) 1
# 返回元素个数
127.0.0.1:6379> scard k1
(integer) 3
# 删除某个元素
127.0.0.1:6379> srem k1 v2 v1
(integer) 2
# 随机吐出一个值
127.0.0.1:6379> spop k1
"v3"
# 吐出n个值
127.0.0.1:6379> sadd k2 v1 v2 v3
(integer) 3
127.0.0.1:6379> srandmember k2 3
1) "v1"
2) "v3"
3) "v2"
9.返回两个集合的元素交集元素
sinter <key1><key2>
10.返回两个集合的并集元素
sunion <key1><key2>
11.返回两个集合的差集元素(key1中的,不包含key2中的)
sdiff <key1><key2>
实例:
127.0.0.1:6379> sadd k1 1 2 3 4
(integer) 4
127.0.0.1:6379> sadd k2 1 3 5 7
(integer) 4
127.0.0.1:6379> sinter k1 k2
1) "1"
2) "3"
127.0.0.1:6379> sunion k1 k2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "7"
127.0.0.1:6379> sdiff k1 k2
1) "2"
2) "4"
# 3.7 Redis哈希(Hash)
概述
Redis hash 是一个键值对集合。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
类似 Java 里面的 Map<String,Object>。
用户 ID 为查找的 key,存储的 value 用户对象包含姓名,年龄,生日等信息,如果用普通的 key/value 结构来存储,主要有以下 2 种存储方式:
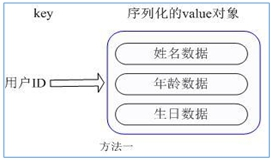
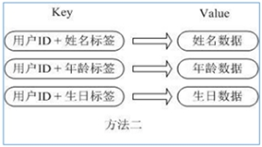
方法一:每次修改用户的某个属性需要,先反序列化改好后再序列化回去。开销较大。
方法二:用户 ID 数据冗余。
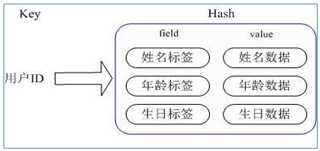
通过 key (用户 ID) + field (属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。
数据结构 Hash 类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当 field-value 长度较短且个数较少时,使用 ziplist,否则使用 hashtable。
# 3.8 哈希常用命令
1.创建一个key添加给field键赋值value
hset <key><field><value>
2.从哈希集合中取出field的value
hget <key><field>
3.批量设置hash的值
hmset <key><field1><value1><field2><value2>
4.查看哈希表key中,给定的field是否存在
hexists <key1><field>
实例:
# 设置单个field的值
127.0.0.1:6379> hset k1 info id
(integer) 1
127.0.0.1:6379> hget k1 info
"id"
# 批量设置
127.0.0.1:6379> hmset k2 id uuid age 20 name lisi
OK
# 查看是否存在
127.0.0.1:6379> hexists k2 id
(integer) 1
5.列出hash集合的所有field
hkeys <key>
6.列出hash集合的所有value
hvals <key>
7.为哈希表key中的域field的值加上增量1 -1
hincrby <key><field><increment>
8.将哈希表key中的域field的值设置为value,当且仅当域field不存在
hsetnx <key><field><value>
实例:
127.0.0.1:6379> hkeys k2
1) "id"
2) "age"
3) "name"
127.0.0.1:6379> hvals k2
1) "uuid"
2) "20"
3) "lisi"
127.0.0.1:6379> hincrby k2 age 1
(integer) 21
# 3.9 Redis 有序集合 Zset
概述
Redis 有序集合 zset 与普通集合 set 非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有 序的,所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
数据结构
SortedSet (zset) 是 Redis 提供的一个非常特别的数据结构,一方面它等价于 Java 的数据结构 Map<String, Double>,可以给每一个元素 value 赋予一个权重 score,另一方面它又类似于 TreeSet,内部的元素会按照权重 score 进行排序,可以得到每个元素的名次,还可以通过 score 的范围来获取元素的列表。
zset 底层使用了两个数据结构:
hash,hash 的作用就是关联元素 value 和权重 score,保障元素 value 的唯一性,可以通过元素 value 找到相应的 score 值。
跳跃表,跳跃表的目的在于给元素 value 排序,根据 score 的范围获取元素列表。
跳跃表
简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis 采用的是跳跃表,跳跃表效率堪比红黑树,实现远比红黑树简单。
对比有序链表和跳跃表,从链表中查询出 51:
有序链表
 要查找值为 51 的元素,需要从第一个元素开始依次查找、比较才能找到。共需要 6 次比较。
要查找值为 51 的元素,需要从第一个元素开始依次查找、比较才能找到。共需要 6 次比较。
跳跃表

从第 2 层开始,1 节点比 51 节点小,向后比较;
21 节点比 51 节点小,继续向后比较,后面就是 NULL 了,所以从 21 节点向下到第 1 层;
在第 1 层,41 节点比 51 节点小,继续向后,61 节点比 51 节点大,所以从 41 向下;
在第 0 层,51 节点为要查找的节点,节点被找到,共查找 4 次。
从此可以看出跳跃表比有序链表效率要高。
# 3.10 zset的常用命令
1.将一个或多个member元素及其score值加入到有序集key当中。
zadd <key><score1><value1><score2><value2>
2.返回有序集key中,下标start stop之间的元素,带上withscores可以让分数一起喝返回值回到结果集。
zrange <key><start><stop> [withscores]
3.返回有序集key中,所有的score值介于min和max之间(包括等于min或max有序集成员按score值递增(从小到大)次序排序)
zrangebyscore key minmax [withscores][limit offset count]
4.从小到大排列
zrevrangebyscore key minmax [withscores][limit offset count]
实例:
127.0.0.1:6379> zadd topn 200 Java 300 C++ 240 Python 400 Golang
(integer) 4
127.0.0.1:6379> zrange topn 0 3
1) "Java"
2) "Python"
3) "C++"
4) "Golang"
127.0.0.1:6379> zrange topn 0 3 withscores
1) "Java"
2) "200"
3) "Python"
4) "240"
5) "C++"
6) "300"
7) "Golang"
8) "400"
127.0.0.1:6379> zrangebyscore topn 200 300 withscores
1) "Java"
2) "200"
3) "Python"
4) "240"
5) "C++"
6) "300"
127.0.0.1:6379> zrevrangebyscore topn 300 200 withscores
1) "C++"
2) "300"
3) "Python"
4) "240"
5) "Java"
6) "200"
5.为元素的score加上增量
zincrby <key><increment><value>
6.删除该集合下,指定的元素
zrem <key><value>
7.统计集合,分数区间内的元素个数
zcount <key><min><max>
8.返回值在集合中的排名,从0开始
zrank <key><value>
实例:
127.0.0.1:6379> zincrby topn 50 Java
"250"
127.0.0.1:6379> zrem topn Python
(integer) 1
127.0.0.1:6379> zcount topn 200 300
(integer) 2
127.0.0.1:6379> zrank topn Java
(integer) 0
# 4. Redis的配置文件详解
# 4.1 Units单位
配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit大小写不敏感
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
# 4.2 网络相关配置
1.Bind配置
默认情况bind=127.0.0.1只能接受本机的访问请求,不写的情况下,无限制接受任何ip地址的访问
生产环境肯定要写你应用服务器的地址;服务器是需要远程访问的,所以需要将其注释掉,如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应。
################################## NETWORK #####################################
# By default, if no "bind" configuration directive is specified, Redis listens
# for connections from all the network interfaces available on the server.
# It is possible to listen to just one or multiple selected interfaces using
# the "bind" configuration directive, followed by one or more IP addresses.
#
# Examples:
#
# bind 192.168.1.100 10.0.0.1
# bind 0.0.0.0 ::1
bind 0.0.0.0
2.protected-mode保护模式
将本机访问保护模式设置no
# By default protected mode is enabled. You should disable it only if
# you are sure you want clients from other hosts to connect to Redis
# even if no authentication is configured, nor a specific set of interfaces
# are explicitly listed using the "bind" directive.
protected-mode no
3.Port端口设置
端口号,默认 6379
port 6379
4.tcp-backlog
设置tcp的backlog,backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列 + 已经完成三次握手队列。
在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。
注意Linux内核会将这个值减小到
/proc/sys/net/core/somaxconn的值(128),所以需要确认增大/proc/sys/net/core/somaxconn和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)两个值来达到想要的效果
# TCP listen() backlog.
#
# In high requests-per-second environments you need an high backlog in order
# to avoid slow clients connections issues. Note that the Linux kernel
# will silently truncate it to the value of /proc/sys/net/core/somaxconn so
# make sure to raise both the value of somaxconn and tcp_max_syn_backlog
# in order to get the desired effect.
tcp-backlog 511
5.tcp-keepalive
对访问客户端的一种心跳检测,每隔n秒检测一次。单位为秒,如果设置为0,则不会进行Keepalive检测,建议设置成60
# A reasonable value for this option is 300 seconds, which is the new
# Redis default starting with Redis 3.2.1.
tcp-keepalive 300
# 4.3 GENERAL通用
1.daemonize
是否为后台进程,设置为yes,守护进程,后台启动
################################# GENERAL #####################################
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
daemonize yes
2.loglevel
指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为notice
四个级别根据使用阶段来选择,生产环境选择notice 或者warning
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
# 4.4 SECURITY安全
1.设置密码
访问密码的查看、设置和取消,在命令中设置密码,只是临时的。重启redis服务器,密码就还原了。 永久设置,需要再配置文件中进行设置。
即找到redis的配置文件—redis.conf文件,然后修改里面的requirepass,这个本来是注释起来了的,将注释去掉,并将后面对应的字段设置成自己想要的密码.
# Warning: since Redis is pretty fast an outside user can try up to
# 150k passwords per second against a good box. This means that you should
# use a very strong password otherwise it will be very easy to break.
#
requirepass 123456
# 5. Redis的发布和订阅
# 5.1 什么是发布和订阅
- Redis 发布订阅 (pub/sub) 是一种消息通信模式:
发送者 (pub) 发送消息,订阅者 (sub) 接收消息。 - Redis 客户端可以订阅任意数量的频道。
# 5.2 Redis的发布订阅
客户端可以订阅频道如下图:
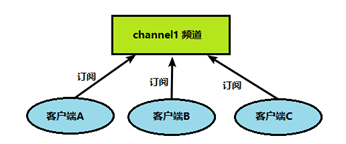
当给这个频道发布消息后,消息就会发送给订阅的客户端:
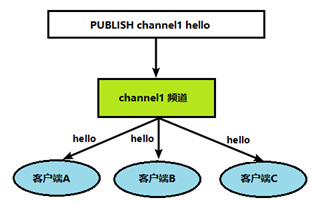
发布订阅命令行实现:
# 打开一个客户端订阅 channel1:
[root@redis etc]# redis-cli
127.0.0.1:6379> subscribe channel1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
1) "message"
2) "channel1"
# 打开另一个客户端,给 channel1 发布消息 hello:
[root@redis /]# redis-cli
127.0.0.1:6379> publish channel1 hello
(integer) 1
# 打开第一个客户端可以看到发送的消息:
[root@redis etc]# redis-cli
127.0.0.1:6379> subscribe channel1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
3) (integer) 1
1) "message"
2) "channel1"
3) "hello"
# 6. 新数据类型
# 6.1 Bitmaps:位操作字符串
# 6.2 简介
现代计算机使用二进制(位)作为信息的基本单位,1个字节等于8位,例如“abc”字符串是有3个字节组成,但实际在计算机内存储时将其使用二进制表示,“abc”分别对应的ASCII码是:97、98、99,对应的二进制分别是01100001、01100010、01100011,如下图

合理地使用位操作能够有效地提高内存使用率和开发效率。
Redis提供了Bitmaps这个“数据类型”可以实现对位的操作:
- Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作,字符串中每个字符对应1个字节,也就是8位,一个字符可以存储8个bit位信息。
- Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。

# 6.3 常用命令
setbit:设置某个偏移量的值(0或1)
SETBIT key offset value
设置offset偏移位的值为value,offset的值是从0开始的,n代表第n+1个bit位置的。
offset参数必须大于或等于0,小于 2^32 (bit 映射被限制在 512 MB 之内)。
value的值只能为0或1**返回值:**指定偏移量原来储存的位。
redis> SETBIT bit 10086 1
(integer) 0
redis> GETBIT bit 10086
(integer) 1
redis> GETBIT bit 100 # bit 默认被初始化为 0
(integer) 0
示例
每个独立用户是否访问过网站存放在bitmaps中,将访问的用户记做1,没有访问的用户记做0,用户id作为offset。
假设现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问,那么当前bitmaps初始化结果如图

users:20220409这个bitmaps中表示2022-04-09这天独立访问的用户,如下
127.0.0.1:6379> setbit users:20220409 1 1
(integer) 0
127.0.0.1:6379> setbit users:20220409 6 1
(integer) 0
127.0.0.1:6379> setbit users:20220409 11 1
(integer) 0
127.0.0.1:6379> setbit users:20220409 15 1
(integer) 0
127.0.0.1:6379> setbit users:20220409 19 1
(integer) 0
getbit:获取某个偏移位的值
GETBIT key offset
获取key所对应的bitmaps中offset偏移位的值。
返回值:0或者1
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> setbit users 1001 1 #设置偏移量1001的bit位的值为1
(integer) 0
127.0.0.1:6379> getbit users 1001 #获取偏移位1001的bit位的值
(integer) 1
127.0.0.1:6379> getbit users 1000 #获取偏移位1000的bit位的值,未设置,返回0
(integer) 0
bitcount:统计bit位都为1的数量
BITCOUNT key [start] [end]
统计字符串被设置为1的bit数,一般情况下,给定的整个字符串都会被进行统计,通过指定额外的start或者end参数,可以让计数只在特定的位上进行,
start和end参数,都可以使用负数值:比如-1表示最后一个位,而-2表示倒数第二个位,以此类推。注意了:start、end是指bit组的字节的下标数,一个直接对应8个bit,所以[a,b]对应的offset范围是[8a,8b+7]
127.0.0.1:6379> flushdb # 清空db,方便测试
OK
127.0.0.1:6379> setbit user 7 1 # 设置user这个bitmaps中偏移量为7的bit为值为1,也就是第8个bit位的值
(integer) 0
127.0.0.1:6379> setbit user 15 1 # 设置user这个bitmaps中偏移量为15的bit为值为1
(integer) 0
127.0.0.1:6379> setbit user 23 1 # 设置user这个bitmaps中偏移量为23的bit为值为1
(integer) 0
127.0.0.1:6379> bitcount user # 获取user这个bitmaps中1的数量
(integer) 3
127.0.0.1:6379> bitcount user 0 1 # 获取[0,1]这个字节内bit位上1的数量,也就是offset是[0,15]的位置上1的数量,所以是2个
(integer) 2
127.0.0.1:6379> bitcount user 0 0 # 获取[0,0]这个字节内bit位上1的数量,也就是offset是[0,7]的位置上1的数量,只有7这个位置,所以是1个
(integer) 1
bittop:对一个多个bitmaps执行位操作
BITOP operation destkey key [key ...]
对一个或多个保存二进制位的字符串
key进行位元操作,并将结果保存到destkey上。
operation可以是AND、OR、NOT、XOR这四种操作中的任意一种:
BITOP AND destkey key [key ...],对一个或多个key求逻辑并,并将结果保存到destkey。BITOP OR destkey key [key ...],对一个或多个key求逻辑或,并将结果保存到destkey。BITOP XOR destkey key [key ...],对一个或多个key求逻辑异或,并将结果保存到destkey。BITOP NOT destkey key,对给定key求逻辑非,并将结果保存到destkey。除了
NOT操作之外,其他操作都可以接受一个或多个key作为输入。**返回值:**保存到
destkey的字符串的长度,和输入key中最长的字符串长度相等。
redis> SETBIT bits-1 0 1 # bits-1 = 1001
(integer) 0
redis> SETBIT bits-1 3 1
(integer) 0
redis> SETBIT bits-2 0 1 # bits-2 = 1011
(integer) 0
redis> SETBIT bits-2 1 1
(integer) 0
redis> SETBIT bits-2 3 1
(integer) 0
redis> BITOP AND and-result bits-1 bits-2
(integer) 1
redis> GETBIT and-result 0 # and-result = 1001
(integer) 1
redis> GETBIT and-result 1
(integer) 0
redis> GETBIT and-result 2
(integer) 0
redis> GETBIT and-result 3
(integer) 1
# 6.4 bitmaps与set比较
假设网站有 1 亿用户, 每天独立访问的用户有 5 千万, 如果每天用集合类型和 Bitmaps 分别存储活跃用户可以得到表:
set 和 Bitmaps 存储一天活跃用户对比
| 数据类型 | 每个用户 id 占用空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| set集合 | 64 位 | 50000000 | 64 位 * 50000000 = 400MB |
| Bitmaps | 1位 | 100000000 | 1 位 * 100000000 = 12.5MB |
很明显, 这种情况下使用 Bitmaps 能节省很多的内存空间, 尤其是随着时间推移节省的内存还是非常可观的。
set 和 Bitmaps 存储独立用户空间对比
| 数据类型 | 一天 | 一月 | 一年 |
|---|---|---|---|
| set集合 | 400MB | 12GB | 144GB |
| Bitmaps | 12.5MB | 375MB | 4.5GB |
但 Bitmaps 并不是万金油, 假如该网站每天的独立访问用户很少, 例如只有 10 万(大量的僵尸用户) , 那么两者的对比如下表所示, 很显然, 这时候使用 Bitmaps 就不太合适了, 因为基本上大部分位都是 0。
| 数据类型 | 每个 userid 占用空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| 集合 | 64 位 | 100000 | 64 位 * 100000 = 800KB |
| Bitmaps | 1 位 | 100000000 | 1 位 * 100000000 = 12.5MB |
# 6.5 HyperLoglog
# 6.6 简介
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站 PV(PageView 页面访问量),可以使用 Redis 的 incr、incrby 轻松实现。但像 UV(UniqueVisitor 独立访客)、独立 IP 数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
数据存储在 MySQL 表中,使用 distinct count 计算不重复个数。
使用 Redis 提供的 hash、set、bitmaps 等数据结构来处理。
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。能否能够降低一定的精度来平衡存储空间?Redis 推出了 HyperLogLog。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8},那么这个数据集的基数集为 {1, 3, 5 ,7, 8},基数 (不重复元素) 为 5。 基数估计就是在误差可接受的范围内,快速计算基数。
# 6.7 命令
pfadd:添加多个元素
pfadd key element [element ...]
向HyperLoglog类型的key中添加一个或者多个元素。
添加一个或者多个元素到key对应的集合中。
返回值:
1:添加成功
0:添加失败
127.0.0.1:6379> flushdb # 清空db方便测试
OK
127.0.0.1:6379> pfadd program java php c c++ # program中添加4个元素[java,php,c,c++],添加成功发,返回1
(integer) 1
127.0.0.1:6379> pfadd program java # 再次添加java,由于已经存在,所以添加失败,返回0
(integer) 0
127.0.0.1:6379> pfadd program java js # 再次添加2个元素,java已经存在了,但是js不存在,添加成功,返回1
(integer) 1
pfcount:获取多个HLL合并后元素的个数
pfcount key1 key2 ...
统计一个或者多个key去重后元素的数量。
示例
127.0.0.1:6379> flushdb # 清空db方便测试
OK
127.0.0.1:6379> pfadd uv1 a b c d e #uv1中5个元素:[a,b,c,d,e]
(integer) 1
127.0.0.1:6379> pfcount uv1 #uv1中数量为5
(integer) 5
127.0.0.1:6379> pfadd uv2 b c d e f #uv2中5个元素:[b,c,d,e,f]
(integer) 1
127.0.0.1:6379> pfcount uv2 #uv2中数量为5
(integer) 5
127.0.0.1:6379> pfcount uv1 uv2 # 获取uv1和uv2去重之后数量合集:[a,b,c,d,e,f],数量为5
(integer) 5
pfmerge:将多个HLL合并后元素放入另外一个HLL
pfmerge destkey sourcekey [sourcekey ...]
将多个
sourcekey合并后放到destkey中。
示例
127.0.0.1:6379> flushdb # 清空db方便测试
OK
127.0.0.1:6379> pfadd uv1 a b c d e #uv1中5个元素:[a,b,c,d,e]
(integer) 1
127.0.0.1:6379> pfcount uv1 #uv1中数量为5
(integer) 5
127.0.0.1:6379> pfadd uv2 b c d e f #uv2中5个元素:[b,c,d,e,f]
(integer) 1
127.0.0.1:6379> pfcount uv2 #uv2中数量为5
(integer) 5
127.0.0.1:6379> pfmerge uv_dest uv1 uv2 #将uv1和uv2合并后放入uv_dest
OK
127.0.0.1:6379> pfcount uv_dest #uv_dest元素个数为6
(integer) 6
# 6.8 Geographic
# 6.9 简介
Reids3.2 中增加了对GEO类型的支持,GEO(Geographic),地理信息的缩写。
该类型,就是元素的 2 维坐标,在地图上就是经纬度,redis基于该类型,提供了经纬度设置、查询、范围查询、距离查询,经纬度Hash等常见操作。
# 6.10 命令
geoadd:添加多个位置的经纬度
geoadd key longitude latitude member [longitude latitude member ...]
longitude latitude member:经度 纬度 名称
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai #添加上海的经纬度
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqing 114.05 22.52 shenzhen 116.38 39.90 beijing #添加重庆、深圳、北京 3 个城市的经纬度
(integer) 3
127.0.0.1:6379> type china:city #发现geo实际上使用zset类型存储的
zset
127.0.0.1:6379> zrange china:city 0 -1
1) "chongqing"
2) "shenzhen"
3) "shanghai"
4) "beijing"
127.0.0.1:6379> zrange china:city 0 -1 withscores
1) "chongqing"
2) "4026042091628984"
3) "shenzhen"
4) "4046432193584628"
5) "shanghai"
6) "4054803462927619"
7) "beijing"
8) "4069885332386336"
两级无法直接添加,一般会下载城市数据,直接通过java程序一次性导入。
有效的经纬度从-180度到180度,有效的维度从-85.05112878度到85.05112878度。
当坐标位置超出指定范围时,该命令将会返回一个错误。
已经添加的数据,是无法再次往里面添加的。
geopos:获取多个位置的坐标值
geopos key member [member ...]
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai #添加上海的经纬度
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqing 114.05 22.52 shenzhen 116.38 39.90 beijing #添加重庆、深圳、北京 3 个城市的经纬度
(integer) 3
127.0.0.1:6379> geopos china:city wuhan beijing chongqing #获取武汉、北京、重庆 3个城市的坐标,由于没有添加武汉的数据,所以没有获取到,其他2个获取到了
1) (nil)
2) 1) "116.38000041246414185"
2) "39.90000009167092543"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
geodist:获取两个位置的直线距离
geodist key member1 member2 [m|km|ft|mi]
单位:
[m|km|ft|mi] -》[米|千米|英里|英尺],默认为米
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai #添加上海的经纬度
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqing 114.05 22.52 shenzhen 116.38 39.90 beijing #添加重庆、深圳、北京 3 个城市的经纬度
(integer) 3
127.0.0.1:6379> geodist china:city beijing chongqing km #获取北京到重庆的直线距离
"1462.9505"
georadius:以给定的经纬度为中心,找出某一半径内的元素
georadius key longitude latitude radius m|km|ft|mi
单位:
[m|km|ft|mi] -》[米|千米|英里|英尺],默认为米
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai #添加上海的经纬度
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqing 114.05 22.52 shenzhen 116.38 39.90 beijing #添加重庆、深圳、北京 3 个城市的经纬度
(integer) 3
127.0.0.1:6379> georadius china:city 110 30 1000 km #在china:city中检索:以经纬度(110,30)为中心,半径为1000km内的位置列表
1) "chongqing"
2) "shenzhen"